 por
por Hace unos meses publiqué dos experimentos sobre Claude Code con el modelo 4.6. Uno comparaba Opus vs Sonnet en los distintos niveles de esfuerzo. Otro probaba si pedirle a la IA que revisara su propio trabajo mejoraba los resultados. Acaba de salir Opus 4.7 y, junto al modelo, un nivel de esfuerzo nuevo que no estaba antes: xHigh. Se sitúa entre High y Max. Decidí repetir exactamente el mismo experimento, con el mismo prompt, en el mismo repositorio, para ver qué cambia realmente.

El experimento, idéntico a la ronda anterior
Para entender de dónde vengo: en el primer post comparé Opus vs Sonnet por niveles de esfuerzo, y en el segundo medí si pedirle al modelo que revisara su propio trabajo mejoraba los resultados. Ambos sobre el mismo repositorio, con el mismo prompt. El prompt es exactamente el mismo que usé al final del segundo experimento, la versión «rigurosa» que en el post anterior conseguía un 57% (4/7) en una sola pasada con 4.6, sin falsos positivos:
Revisa el flujo completo de GET /users/:user/stats y dime qué política de cache tiene actualmente. Por favor, quiero hacerlo de una sola pasada, así que quiero que lo revises todo que esté bien antes de dar la respuesta, quiero evitar errores o flujos erróneos.
El repositorio es el mismo: steamplaytime-backend, un backend NestJS real con CQRS, MikroORM y una política de caché que tiene, a propósito, varias capas y alguna inconsistencia de diseño. No es un ejemplo de libro: es código de un proyecto que uso. Los 7 criterios de evaluación también son los mismos del experimento anterior:
- Detectar la capa de caché del
UserAlias(TTL 1 hora) - Detectar la capa de caché del
user_stats_view(TTL 24 horas) - Identificar que no hay caché HTTP (ni
Cache-Controlni ETag) - Detectar la inconsistencia: el TTL de 24 h es inalcanzable porque ambos timestamps se refrescan a la vez
- Detectar los campos duplicados
updatedAt/updatedOnen la misma tabla - Notar que
UserHasPrivateProfileErrorestá definido pero nadie lo lanza - Detectar el doble
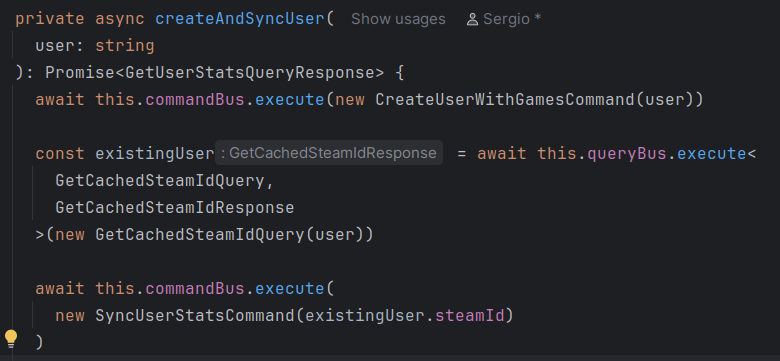
GetCachedSteamIdQueryredundante en la rama de creación
En la ronda con 4.6, y usando este mismo prompt riguroso, el techo absoluto en una sola pasada fue 4 de 7 (el 57% del segundo post). Solo 2 de 21 configuraciones y siempre combinando Max con self-review, nunca en una única pasadam detectaron la inconsistencia nº 4 (el dead code del TTL de 24 h). Esa era la pregunta trampa del experimento.
Los niveles de esfuerzo en 4.7
Con 4.6 había cuatro niveles: Low, Medium, High y Max. Con 4.7 aparece uno nuevo:
/model
Set model to Opus 4.7 (1M context) with low effort
Set model to Opus 4.7 (1M context) with medium effort
Set model to Opus 4.7 (1M context) with high effort
Set model to Opus 4.7 (1M context) with xhigh effort ← nuevo
Set model to Opus 4.7 (1M context) with max effortxHigh se sitúa entre High y Max. Anthropic no lo ha documentado de forma muy llamativa, así que la pregunta interesante es: ¿aporta algo real, o es un nivel intermedio que podrías saltarte?
Resultados por nivel de esfuerzo
Low: cae en el mismo error que antes
● Política de cache actual de GET /users/:user/stats:
TTL: 24 horas (constante CACHE_MAX_AGE_HOURS = 24 en GetUserStatsController.ts:17).Low lee un único archivo, ve la constante CACHE_MAX_AGE_HOURS = 24 y declara que el TTL es de 24 horas. No detecta la capa del UserAlias en absoluto. Es el mismo patrón de atajo que ya vi en 4.6 Low: se queda con el primer número que ve. Como curiosidad, sí identifica que no hay cabeceras HTTP, que el refresh es bloqueante y que hay queries redundantes. Pero la respuesta principal está incompleta. Puntuación: 3 / 7.
Medium: el salto más grande respecto a 4.6
Aquí es donde 4.7 se despega claramente. Después de leer 12 archivos, Medium no solo detecta las dos capas, sino que llega a la conclusión clave:
La ventana de 24h es prácticamente inalcanzable: el CreateUserWithGamesCommand reescribe
alias.updatedOn = nowen cada refresh, y ese mismo flujo siempre ejecuta el SyncUserStatsCommand acto seguido. Por tanto, siempre que el alias está cacheado (<1h), el view fue sincronizado en esa misma ventana, por lo queisStalenunca dispara en la práctica. El TTL real es 1 hora.
Esto es exactamente la inconsistencia que antes solo 2 de 21 tests detectaban con 4.6, y nunca en la primera pasada de Medium. Aquí sale sin pedir revisión, sin self-review, sin prompt especial. Además identifica la confusión entre updatedAt y updatedOn, el doble lookup del alias y la ausencia de caché HTTP. Tardó 1 minuto y 40 segundos. Puntuación: 6 / 7.
High: más educado, menos afilado
Curiosa paradoja, y es la misma que vi con 4.6: High produce una respuesta más estructurada y más larga, pero suaviza la conclusión más importante.
El check de 24 h solo dispara en una situación anómala: Create completó pero Sync falló. No es inútil, pero tampoco es la política de caché «real». La real es 1 hora marcada por el alias.
Detecta la inconsistencia, sí, pero la presenta como una «red de seguridad» en lugar de llamarla por su nombre. Es una regresión de claridad respecto a Medium, aunque el resto de criterios los cumple igual. Puntuación: 5,5 / 7.
xHigh: recupera la agudeza y añade más
Aquí es donde el nivel nuevo se justifica. xHigh delega primero en un subagente de exploración (31 tool uses, 52,7k tokens), y al volver con el contexto completo tira directo al grano:
El TTL de 24 h es inalcanzable (dead code).
CreateUserWithGamesCommandSIEMPRE se ejecuta junto aSyncUserStatsCommand.
Vuelve a llamar al problema por su nombre «dead code» como hacía Medium. Pero además encuentra algo que ningún nivel anterior había visto: un error de dominio definido pero nunca lanzado.
UserHasPrivateProfileErrorestá definido pero nadie lo lanza ni lo captura (verificado por grep en todo src/). Es código nuevo (untracked en git).
Eso es el criterio nº 6 de la lista. Era mi pregunta trampa secundaria, y xHigh la destapa sin que la pida. Tardó 2 minutos y 38 segundos. Puntuación: 7 / 7.
Max: mismo resultado, más ceremonia
Max llega al mismo 7 / 7, pero con un comportamiento visible distinto: verbaliza cada paso.
● Voy a revisar el flujo completo del endpoint GET /users/:user/stats...
● Voy a explorar los handlers y queries en paralelo...
● Continúo explorando las piezas claves...
● Voy a revisar la política de caché y la lógica isCached...
● Continúo con UserAlias, UserStatsPolicy y el data finder de sync.
● Reviso si hay cache HTTP a nivel de cabeceras...
● Verifico si hay algún flujo que actualice el UserAlias sin re-sincronizar stats...Cada paso lleva su propia ronda de Read y Grep. Es metódico y transparente, pero para este prompt concreto no descubre nada que xHigh no hubiera encontrado ya. El coste adicional no compra hallazgos adicionales. Puntuación: 7 / 7.
¿Por qué xHigh merece su propio apartado?
Porque es el primer nivel que, en una sola pasada, detecta todos los puntos del checklist incluyendo los dos trampas (el dead code del TTL de 24 h y el error de dominio sin lanzar). Con 4.6, detectar los dos requería:
- O bien Opus Max con dos rondas de self-review (cuesta ~$0,50 y dos prompts adicionales)
- O bien un prompt muy cuidado pidiendo rigor desde el inicio
Con 4.7 xHigh, en una sola pregunta sin ningún truco, sale todo. Y a diferencia de Max, no necesita verbalizar cada paso: delega en subagentes en paralelo y vuelve con la respuesta construida. Mi lectura: xHigh no es un relleno entre High y Max. Es el nivel donde el modelo puede lanzarse a planificación paralela sin convertirse en un stream of consciousness como hace Max. En la práctica, es el sweet spot para análisis de código medianamente complejo.
4.6 vs 4.7: el cambio que no está donde se suele mirar
Mismo prompt riguroso, misma métrica, una sola pasada. El techo de 4.6 en una sola pasada con este prompt era 4 / 7. Para pasar de ahí había que añadir self-review encima de Max. El cambio más llamativo no está en el techo, está en el suelo
| Nivel | 4.6 (prompt riguroso) | 4.7 (prompt riguroso) | Diferencia |
|---|---|---|---|
| Low | ~2 / 7 | 3 / 7 | Similar: el atajo a una sola capa sigue presente |
| Medium | ~3 / 7 | 6 / 7 | Salto grande: detecta el dead code sin ayuda |
| High | ~3 / 7 | 5,5 / 7 | Mejora, pero repite el patrón de suavizar conclusiones |
| xHigh | — | 7 / 7 | Nivel nuevo |
| Max | ~4 / 7 | 7 / 7 | Rompe el techo del experimento anterior |
Lo importante: para alcanzar el equivalente de 6-7 / 7 con 4.6 había que encadenar Max con una o dos rondas de «revisa tu propio trabajo». Con 4.7, Medium lo hace en una sola pasada usando el mismo prompt, y xHigh / Max llegan al 7 / 7 sin self-review. En el día a día, eso pesa más que cualquier número de benchmark.
Lo que no cambia
- La paradoja del High: sigue siendo el nivel con más probabilidad de suavizar la respuesta. Más tokens no es más agudeza.
- Low sigue siendo peligroso para análisis de flujo: se queda con la primera pista que ve y la convierte en conclusión.
- Max verbaliza más de lo necesario: es útil para auditar el razonamiento, pero no descubre más que xHigh cuando la tarea tiene un alcance definido.
Coste y cuándo usar cada nivel
| Nivel | Buen uso | Mal uso |
|---|---|---|
| Low | Preguntas factuales, grep con interpretación, qué hace tal función | Cualquier cosa que requiera cruzar más de un archivo con criterio |
| Medium | Análisis de flujo en una sola pasada, revisión de una política de caché, refactor pequeño | Cuando el problema pide explorar ramas que no son obvias |
| High | Tareas de implementación donde quieres estructura en la respuesta | Detección de inconsistencias sutiles (paradójicamente peor que Medium) |
| xHigh | Análisis completo con trampa: dead code, bugs latentes, inconsistencias de diseño | Preguntas simples; es sobredosis |
| Max | Auditoría donde quieres ver cada paso del razonamiento explícito | Trabajo diario; el sobrecoste no compensa frente a xHigh |
Conclusión
Claude Opus 4.7 no es una mejora incremental uniforme sobre 4.6. Es una redistribución: el Medium se lleva la mayor parte de la mejora práctica, y el nivel xHigh abre un espacio que antes no existía, entre «rápido» y «ceremonioso».
Para el trabajo diario, el cambio más útil es poder confiar en Medium para análisis que antes exigían Max + reviews. Para tareas donde quieres detectar el dead code, el bug latente o la inconsistencia que los compañeros han dejado pasar, xHigh es el nivel nuevo al que merece la pena subir.
Max sigue teniendo sentido cuando necesitas ver el razonamiento intermedio como por ejemplo, para documentar una auditoría o validar con un humano cada paso, pero ya no es la herramienta por defecto para «análisis profundo». Mi configuración por defecto ha cambiado: Medium para el 80% del trabajo, xHigh cuando huelo que hay un bug que no me están contando, Max solo cuando el entregable es el razonamiento, no el resultado. Como siempre: la IA es la herramienta, saber qué nivel pedirle sigue siendo parte del trabajo. ¿Has repetido el experimento con tu propio repositorio? Los comentarios están abajo.

