por
por Llevo semanas viendo el mismo mensaje en diferentes formatos: «Corre Claude Code completamente gratis, offline, sin pagar ni un solo euro». Cursor cuesta 20€ al mes, GitHub Copilot 10€, Ollama + Claude Code 0€.
Decidí probarlo en mi propio proyecto, el mismo repositorio que uso para los experimentos de este blog. La idea era simple: reproducir exactamente los pasos que prometen estas publicaciones y documentar qué pasa realmente.
Lo que encontré tiene tres capas distintas, y ninguna es la que promete el titular. Si quieres ver los anteriores post, los puedes encontrar en:
Opus vs Sonnet en Claude Code: qué cambia realmente entre modelos y niveles de esfuerzo
¿Mejora la IA si le pides que revise su propio trabajo? Lo probé con Claude Code
El entorno de prueba
Antes de entrar en los resultados, el hardware importa más de lo que parece en estos setups. Mi máquina:
- RAM: 32 GB
- GPU: AMD RX 9060 XT (RDNA 4) con 16 GB VRAM
- SO: Linux
- Ollama: v0.20.3 instalado como servicio systemd
Un detalle importante: la 9060 XT es una GPU muy reciente. Cuando comprobé si Ollama la detectaba, y sí, el servicio de Ollama ya la había reconocido con ROCm:
inference compute id=GPU-f7aef789 library=ROCm compute=gfx1200
name=ROCm0 description="AMD Radeon Graphics" total="15.9 GiB"gfx1200 es la arquitectura RDNA 4. Ollama la detectó sin configuración adicional en Linux. Primer punto a favor del setup.
Los pasos exactos para montar el entorno

Reproduciendo lo que circula en redes, el proceso es este:
1. Instalar Ollama
curl -fsSL https://ollama.com/install.sh | shEn Linux se instala como servicio systemd y arranca automáticamente. No hace falta ejecutar ollama serve manualmente.
2. Descargar un modelo de código
ollama pull qwen2.5-coder:7bSon 4,7 GB. Con una conexión decente tarda unos minutos. El modelo queda en local y no necesita internet para funcionar después.
3. Redirigir Claude Code al backend local
export ANTHROPIC_AUTH_TOKEN=ollama
export ANTHROPIC_BASE_URL=http://localhost:11434
claude --model qwen2.5-coder:7bEl token es un placeholder, no se usa ninguna API de Anthropic. Claude Code se lanza apuntando al servidor local de Ollama.
Primera prueba: qwen2.5-coder:7b
El modelo más recomendado en este tipo de setups. Diseñado específicamente para tareas de código, liviano, rápido en GPU.
Le lancé el mismo prompt que usaría en mi trabajo habitual con Claude Code:
Revisa el flujo completo de GET /users/:user/stats y dime qué política de cache tiene actualmente. Quiero hacerlo de una sola pasada, así que revisa todo antes de dar la respuesta.
La respuesta del modelo:
{"name": "get_user_stats_cache_policy", "arguments": {}}Nada más. El modelo intentó llamar a una herramienta, pero en lugar de ejecutarla imprimió el JSON crudo en pantalla. No leyó ningún archivo. No navegó el repositorio. No devolvió ninguna respuesta útil.
Volví a intentarlo. Mismo resultado.
Segunda prueba: qwen3:14b
Mismo prompt, modelo más grande y más reciente. 9,3 GB, entra en los 16 GB de VRAM de la GPU. Tardó en cargar pero la GPU trabajó (el ventilador lo dejó claro).
Esta vez la respuesta fue diferente, pero igualmente inútil:
La política de cache actual depende de la configuración más específica en el flujo (CDN > API Gateway > Proxy inverso > Servidor). Si no se encuentra ninguna configuración explícita, la política por defecto sería no-cache (HTTP/1.1)… Recomendación: revisar directamente los encabezados de respuesta HTTP del endpoint en producción usando herramientas como Postman o cURL.
El modelo respondió con confianza. Sin leer un solo archivo. Sin usar ninguna herramienta. Inventó una respuesta genérica sobre capas de cache (CDN, API Gateway, Nginx) que no existen en este proyecto. Todo plausible, todo falso.
Dos fallos distintos con dos modelos distintos:
| Modelo | Fallo observado |
|---|---|
| qwen2.5-coder:7b | Intenta llamar herramientas pero imprime JSON crudo |
| qwen3:14b | Ignora las herramientas, alucina respuesta genérica |
¿Por qué falla?
Claude Code no es solo una interfaz que manda texto a un modelo. Es un sistema agéntico que depende de tool calling: el modelo recibe un prompt con definiciones de herramientas (leer archivos, ejecutar comandos, buscar en el repositorio) y tiene que responder invocando esas herramientas con el formato correcto.
El problema es que ese protocolo de herramientas está diseñado para los modelos Claude de Anthropic. Cuando se apunta Claude Code a Ollama, hay un mismatch de formato: Claude Code envía requests en el formato de la API de Anthropic, y Ollama habla principalmente formato OpenAI. Los modelos locales reciben las definiciones de herramientas, pero no siguen el protocolo de invocación que Claude Code espera.
Resultado: o imprimen el JSON crudo (qwen2.5-coder), o lo ignoran completamente y responden sin contexto real (qwen3).
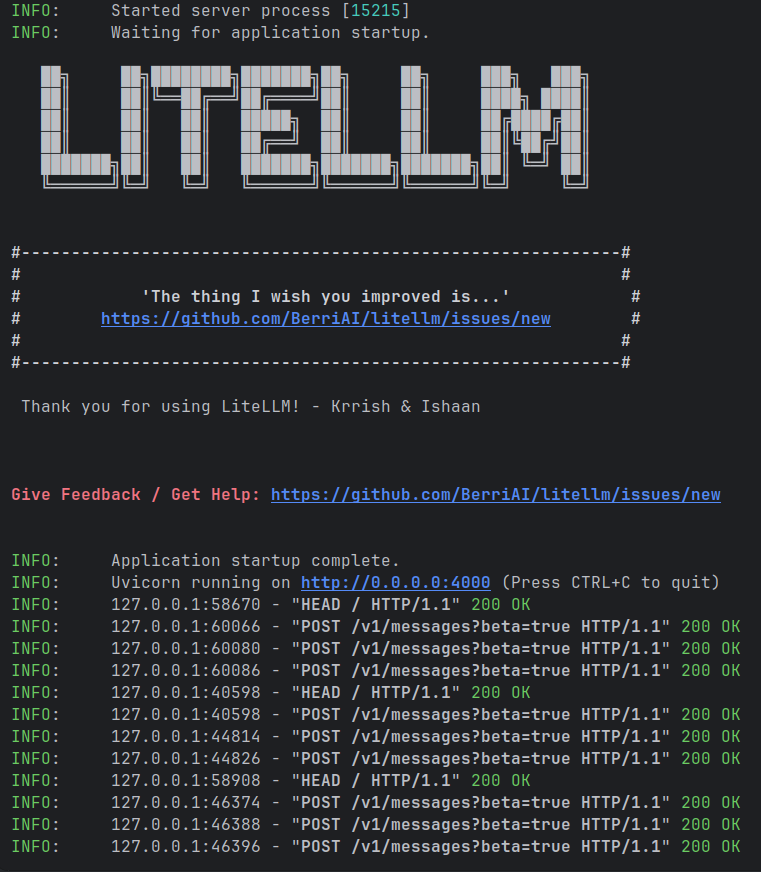
El tercer intento: LiteLLM como proxy
La solución documentada para este problema es poner un proxy en medio que traduzca entre los dos formatos. LiteLLM es la herramienta estándar para esto.
uvx --with "litellm[proxy]" litellm --model ollama/qwen3:14b --port 4000export ANTHROPIC_AUTH_TOKEN=litellm
export ANTHROPIC_BASE_URL=http://localhost:4000
claude --model ollama/qwen3:14bEl proxy arrancó correctamente. Los logs mostraban POST /v1/messages?beta=true 200 OK, es decir, Claude Code enviaba los requests y LiteLLM los recibió. Con el mismo prompt, este fue el resultado:
● {}Respuesta vacía. Probé con llama3.1:8b, que tiene soporte nativo de function calling de Meta y tampoco me funcionó.
LiteLLM resuelve el mismatch de formato HTTP, pero no puede arreglar cómo el modelo interpreta las instrucciones de herramientas. El modelo recibe las definiciones correctamente, pero no sabe qué hacer con ellas según el contrato que espera Claude Code.
Resultados reales de las pruebas
| Setup | Modelo | Tool calling | Respuesta útil |
|---|---|---|---|
| Ollama directo | qwen2.5-coder:7b | JSON crudo impreso | No |
| Ollama directo | qwen3:14b | Ignorado | No (alucinación) |
| LiteLLM proxy | qwen3:14b | Respuesta vacía {} | No |
| LiteLLM proxy | llama3.1:8b | Respuesta vacía {} | No |
| Anthropic API | Claude Sonnet | Funciona | Sí |
El único setup que funciona es el original: Claude Code con los modelos de Anthropic.
Pero entonces, ¿qué es lo que dice LinkedIn?
Mientras investigaba los fallos me encontré con un enfoque completamente diferente al del hype que circula en redes. Un ingeniero publicaba resultados reales de un proyecto TypeScript: 12 archivos cambiados, 90% menos tokens consumidos de Claude. La clave era que no estaba reemplazando Claude Code con Ollama. Estaba haciendo algo distinto.
En su pipeline:
- Claude analiza el repositorio, entiende el contexto, crea un plan detallado
- Ese plan se pasa a un modelo local de Ollama
- Ollama escribe el código siguiendo las instrucciones sin necesidad de entender el repo
La diferencia es fundamental. El modelo local no necesita tool calling ni contexto largo. Solo recibe: «escribe esta función con estos parámetros, que reciba X y devuelva Y, siguiendo este patrón que ya existe en el archivo Z». Para eso sí es suficientemente bueno, aunque no como Claude Code nativo.
Las tres capas del hype
| Afirmación | Realidad |
|---|---|
| «Claude Code + Ollama, zero cost, offline» | No funciona. El tool calling es incompatible independientemente del modelo o proxy que uses. |
| «Claude piensa, Ollama ejecuta» | Válido en concepto, pero sigue requiriendo la API de Anthropic y un setup manual considerable. |
| «90% menos tokens» | Posible en tareas repetitivas de generación de boilerplate. No aplica a análisis complejo. |
Conclusión
Claude Code no es una interfaz genérica que funciona con cualquier modelo. Es un sistema agéntico co-diseñado con los modelos Claude de Anthropic. El protocolo de herramientas, la forma en que el modelo interpreta las instrucciones de lectura de archivos y ejecución de comandos, está calibrado para esos modelos específicos. Separar la interfaz del modelo rompe la experiencia, y eso es lo que vimos en todas las pruebas.
El enfoque híbrido tiene más sentido técnico: Claude para el razonamiento y la exploración del repositorio, un modelo local para la generación de código mecánico. Pero eso no es «zero cost» ni «offline». Sigue consumiendo tokens de Anthropic para la parte que más importa, y el ahorro real depende de qué proporción de tu trabajo es generación de boilerplate frente a razonamiento real sobre el código.
Para los proyectos donde la mayor parte del tiempo de Claude se va en decisiones arquitectónicas, debugging complejo o análisis de flujos, el ahorro del pipeline híbrido va a ser marginal. Para proyectos donde generas muchos tests, muchos CRUD endpoints o mucho scaffolding repetitivo, el planteamiento de ai-orchestrator puede llegar a tener cierto sentido.
Como siempre: la IA es la herramienta, no el arquitecto. Saber cuándo usar cada nivel es el trabajo que sigue siendo tuyo.
¿Has probado algún setup similar con resultados diferentes? Los comentarios están abajo.