 por
por Llevo meses investigando, probando herramientas y viendo cómo la comunidad de desarrollo evoluciona alrededor de una idea que parece simple pero que tiene muchos matices: escribir una especificación antes de pedirle a la IA que genere código. Esto es lo que se ha dado en llamar Spec-Driven Development (SDD), y creo que ha llegado el momento de poner por escrito todo lo que he aprendido.
Porque sí, la idea suena bien. Pero la realidad es bastante más compleja de lo que la mayoría de tutoriales cuentan.
El problema que intenta resolver el SDD
Todos hemos pasado por esto. Abres tu editor, le dices a Claude o a Copilot algo como «añade la funcionalidad de checkout», y lo que recibes es… algo. Ha elegido una librería de cálculo que no es la nuestra, ha asumido que los impuestos (IVA) se calculan al final en lugar de por cada item, y de paso te ha implementado un sistema de expiración de reserva de 15 minutos que nadie le había pedido y de paso te ha dockerizado todo el proyecto sin tu permiso.
Esto es lo que muchos llaman vibe coding: lanzar prompts y ver qué sale. Y funciona sorprendentemente bien para prototipos rápidos y proyectos pequeños. El problema aparece cuando intentas escalar, mantener el código, o trabajar en equipo. El código que genera la IA sin dirección clara tiende a convertirse en espagueti, y cada sesión nueva es como empezar de cero porque el agente no tiene memoria de tus decisiones anteriores.
El SDD propone una solución: antes de escribir código, escribe una especificación. Un documento que defina qué vas a construir, por qué, cuáles son las restricciones, y cómo se descompone el trabajo en tareas. La IA deja de adivinar y empieza a ejecutar un plan concreto.

Suena lógico. Pero el diablo está en los detalles.
Qué es realmente una especificación en este contexto
Aquí es donde empieza la confusión. El término «spec» se usa de maneras muy diferentes según a quién le preguntes. He visto gente usarlo como sinónimo de «prompt detallado», otros lo equiparan a un PRD (Product Requirements Document), y algunos lo llevan al extremo de convertirlo en el artefacto principal del proyecto, por encima del propio código.
En cierto modo, el SDD es una especie de BDD para LLMs: describimos comportamiento en lenguaje natural, pero el consumidor ya no es solo el humano ni el framework de testing, sino un agente generativo que traduce intención en implementación.
Después de investigar bastante, creo que una definición útil sería esta: una spec es un artefacto estructurado, escrito en lenguaje natural, que describe el comportamiento del software y sirve como guía para los agentes de IA. No es un prompt. No es documentación genérica. Es un contrato entre tú y el agente sobre qué se va a construir.
Una buena spec normalmente incluye:
- El por qué: por qué estamos construyendo esto, cuál es el problema que resolvemos
- El qué: qué funcionalidad concreta vamos a implementar
- Las restricciones: qué librerías usar, qué patrones seguir, qué NO hacer
- Lo que está fuera de alcance: tan importante como lo anterior, porque los agentes son entusiastas y tienden a implementar de más
- Las tareas: el trabajo descompuesto en pasos discretos y verificables
La diferencia clave con un PRD tradicional es que la spec está diseñada para ser consumida por un agente de IA, no solo por humanos. Incluye el nivel de detalle técnico que un agente necesita para no tener que adivinar.
Los tres niveles de SDD que he identificado
Leyendo a Birgitta Böckeler (Distinguished Engineer en Thoughtworks), me gustó mucho cómo categoriza el uso de la IA en tres niveles. Adaptándolo, creo que nos ayuda a entender dónde estamos y a dónde queremos ir..
Nivel 1: Spec-first (la especificación va primero)
Es el nivel más básico y, sinceramente, el más útil para la mayoría de casos. Escribes una spec antes de empezar a codificar, la usas como guía durante la implementación, y cuando terminas, la spec puede descartarse o archivarse. La próxima vez que trabajes en esa funcionalidad, escribes una nueva spec que describa los cambios.
Es como darle un briefing detallado a un desarrollador junior antes de que empiece a trabajar. No le dices «añade autenticación». Le dices «implementa autenticación JWT con tokens de acceso de 1 hora y refresh tokens de 7 días, usando la librería jose, almacenando usuarios en PostgreSQL vía Prisma, sin añadir nuevas dependencias, sin OAuth, sin recuperación de contraseña por ahora».
Nivel 2: Spec-anchored (la especificación se mantiene viva)
Aquí la spec no se descarta después de implementar. Se mantiene como documento vivo que evoluciona junto con la funcionalidad. Cuando necesitas hacer cambios, primero actualizas la spec y luego implementas.
Es un paso más de compromiso. Tienes que mantener sincronizados dos artefactos (la spec y el código), pero a cambio tienes una fuente de verdad que facilita la evolución del software a largo plazo.
Nivel 3: Spec-as-source (la spec es el código fuente)
Este es el nivel más ambicioso y, honestamente, el más experimental. La idea es que el humano solo edita la spec, nunca toca el código directamente. El código se genera automáticamente desde la spec y lleva marcas como // GENERATED FROM SPEC - DO NOT EDIT.
He visto implementaciones donde hay un mapeo 1:1 entre archivos de spec y archivos de código. Cambias la spec, regeneras el código. Es fascinante conceptualmente, pero plantea problemas serios que comentaré más adelante.
El espectro de la especificación: de cero a tres pasos
Otra forma de ver esto es por la cantidad de documentos que generas antes de empezar a programar. He observado cuatro variantes:
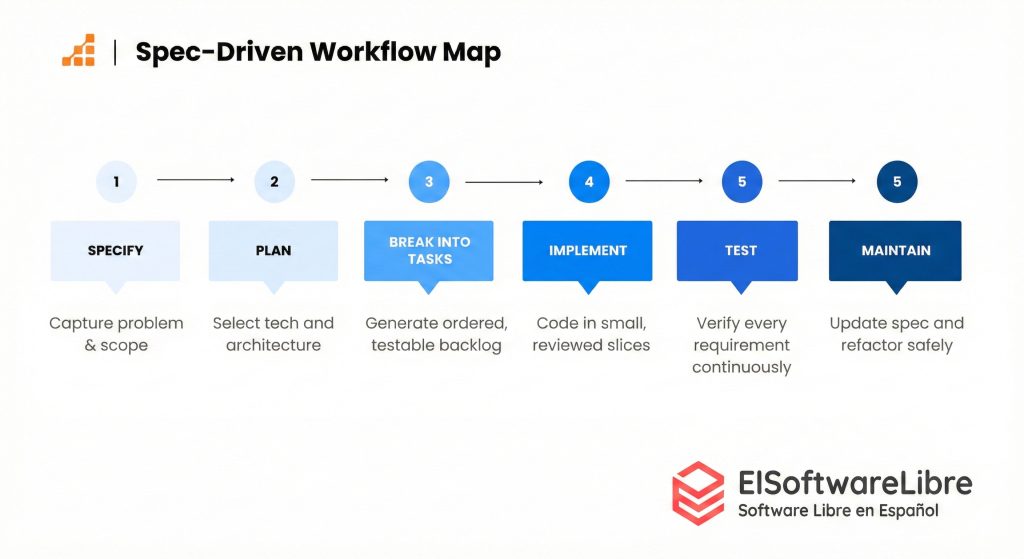
Cero pasos: la especificación está implícita en el prompt. Es el vibe coding puro. «Hazme una app de flashcards». Funciona para prototipos.
Un paso: un único documento que recoge todo (problema de negocio, solución técnica, criterios de aceptación). Simple y efectivo si descompones bien el problema en funcionalidades pequeñas.
Dos pasos: separas la visión de negocio de la especificación técnica. Un archivo define el qué, otro define el cómo. Esto te permite explorar diferentes soluciones técnicas para el mismo problema de negocio.
Tres pasos: añades un tercer documento con las tareas desglosadas. Es lo que implementan herramientas como Kiro o Spec-Kit: requisitos, diseño, tareas. Cada paso genera un artefacto que puedes revisar de forma independiente.
La elección entre estas variantes no es «más pasos = mejor». Depende de la complejidad del problema. Usar tres pasos para corregir un bug es como matar moscas a cañonazos.
Las herramientas que he probado (y lo que he aprendido de cada una)
Kiro (Amazon)
Kiro es la más ligera de las que he explorado. Te guía a través de tres pasos dentro de su editor basado en VS Code: Requisitos, Diseño, Tareas. Los requisitos se estructuran como historias de usuario con criterios de aceptación en formato GIVEN/WHEN/THEN, como si fuesen tests de comportamiento.
Lo bueno: es intuitivo, el flujo de tres documentos es fácil de entender, y no genera una cantidad abrumadora de archivos.
El problema: aplica el mismo workflow a todo. Cuando lo probé con un bug en el redondeo de precios de precios de hotel, el cual tardas 2 minutos en arreglar a mano, Kiro me generó 3 historias de usuario con 7 criterios de aceptación. Es como pedirle un informe de impacto medioambiental para cambiar una bombilla.
Spec-Kit (GitHub)
Spec-Kit es la propuesta de GitHub. Se instala como CLI y genera una estructura de workspace para diferentes asistentes de código. Funciona con slash commands (/specify, /plan, /tasks) y crea un sistema bastante elaborado con constitución, templates, scripts y checklists.
Lo bueno: es muy completo, orientado a TDD, crea ramas de git automáticamente para cada spec, y la idea de una «constitución» (principios inmutables del proyecto) es potente.
El problema: Más documentos no garantizan mejor arquitectura. El proceso de ‘review’ se puede volver redundante porque acabas leyendo lo mismo en tres sitios distintos (requisitos, plan y tareas). En una comparativa que hice, perdí 45 minutos en el ritual de preparación para algo que, mediante pair programming con la IA, resolví en tres interaciones.
Además, hubo momentos en que el agente simplemente ignoró las especificaciones que le habíamos dado. Tenía notas detalladas sobre clases existentes en el codebase, pero en lugar de reutilizarlas, las generó de nuevo creando duplicados. Las ventanas de contexto son más grandes, sí, pero eso no garantiza que la IA preste atención a todo lo que hay dentro.
Claude Code (Anthropic) y el enfoque de ‘Checkpointing’
Es, posiblemente, la herramienta que mejor entiende el concepto de la especificación como fuente de verdad. En lugar de ir directo al código, fuerza una fase de ‘Thinking’ donde genera un plan de ejecución detallado que actúa como contrato. Si el plan es sólido, el código suele serlo; si el plan es flojo, el resultado es mediocre.
Lo interesante: Al trabajar sobre un plan estructurado antes de escribir un solo archivo, reduce drásticamente las alucinaciones y siempre tiene ese contexto para volver en caso de disparidad.
El problema de fondo: Esto me recuerda mucho a los antiguos generadores de código basados en WSDL o SOAP. La idea de que el documento define el código es potente, pero a mi parecer, peligrosa. Con los LLMs perdemos el determinismo, ya que la misma especificación puede darte tanto una implementación brillante como una diferente en tan solo una iteración. Es un trade-off entre la agilidad de la IA y la rigidez de un contrato formal que aún estamos intentando equilibrar en el equipo.
Los problemas reales del SDD que nadie menciona en los tutoriales
Un único workflow no sirve para todos los tamaños de problema
Este es quizá el problema más fundamental. Las herramientas de SDD ofrecen un flujo de trabajo único y opinado, pero los problemas de software vienen en tamaños muy diferentes. Corregir un bug de CSS no necesita requisitos, diseño y tareas. Añadir autenticación a una app grande, probablemente sí.
Un SDD efectivo necesitaría al menos variantes de workflow para diferentes escalas: correcciones rápidas, funcionalidades pequeñas, funcionalidades grandes, y refactorizaciones arquitectónicas.
Revisar markdown puede ser peor que revisar código
Esto suena contraintuitivo, pero es mi experiencia directa. Algunas herramientas generan tantos archivos markdown intermedios que el esfuerzo de revisión supera al de revisar el código directamente. Y muchos de esos archivos son repetitivos o contienen información que ya estaba en el codebase.
Prefiero revisar 200 líneas de código que 5 documentos de markdown que dicen lo mismo de formas ligeramente diferentes.
La falsa sensación de control
Tener specs, checklists, constituciones y templates da una sensación reconfortante de que todo está bajo control. Pero la realidad es que los agentes de IA siguen sin seguir instrucciones de forma perfecta. He visto agentes ignorar restricciones explícitas, generar código duplicado a pesar de tener documentación sobre el código existente, y ser excesivamente entusiastas siguiendo algunas instrucciones mientras ignoran otras.
La historia nos ha enseñado que la mejor forma de mantener el control sobre lo que construimos es trabajar en pasos pequeños e iterativos. Llenar el contexto de documentación up-front no sustituye a la iteración rápida.
La separación funcional/técnico es más difícil de lo que parece
Uno de los principios del SDD es separar la especificación funcional de la técnica. La aspiración es que eventualmente podríamos cambiar de stack tecnológico manteniendo la misma spec funcional. En la práctica, la línea entre «qué» y «cómo» es borrosa. He visto tutoriales y documentación que no son consistentes sobre cuándo mantenerse en el nivel funcional y cuándo añadir detalles técnicos.
Y seamos honestos: como industria, no tenemos un buen track record separando requisitos de implementación. Las historias de usuario que mezclan ambos conceptos son la norma, no la excepción.
Lo que sí funciona: mi enfoque híbrido
Después de toda esta investigación y experimentación, mi conclusión es que el SDD puro (con todos sus frameworks y ceremonias) es excesivo para la mayoría de situaciones, pero el vibe coding puro tampoco escala. Lo que funciona es un enfoque híbrido, adaptado al tamaño del problema.
Paso 1: Investiga antes de especificar
Antes de escribir una sola línea de spec, ten una conversación con la IA. No en modo agente de código, sino en modo consultor. Explícale qué quieres construir y pídele que te haga preguntas para clarificar. Este paso es increíblemente valioso porque la IA te forzará a pensar en aspectos que quizá no habías considerado: escalabilidad, casos límite, decisiones de arquitectura, integraciones.
Una técnica que funciona muy bien es el meta-prompt: en lugar de pedirle a la IA que haga algo directamente, le pides que genere el prompt óptimo para esa tarea. Tú describes el objetivo y el resultado esperado, y la IA genera un prompt mucho más específico y detallado que el que tú habrías escrito.
Otra técnica potente es «pregunta al experto»: le pides a la IA que analice tu proyecto y te haga todas las preguntas que considere necesarias antes de proponer una solución. Esto es especialmente útil en áreas donde no eres experto. Las preguntas que genera un LLM sobre modelado de datos, ciberseguridad o internacionalización suelen ser sorprendentemente exhaustivas.
Paso 2: Define el contexto del proyecto, no solo de la tarea
Aquí es donde entra algo más permanente que una spec individual: el contexto del proyecto. Esto incluye:
- Reglas del proyecto (rules files, CLAUDE.md, .cursorrules): convenciones de código, patrones a seguir, librerías preferidas
- Arquitectura general: cómo está estructurado el proyecto, qué componentes existen, cómo se comunican
- Stack tecnológico: que no sea el agente quien decida si usar React o Vue
Este contexto se configura una vez y se usa en todas las sesiones. Es diferente a la spec de una tarea concreta.
Y si trabajas con herramientas externas, conectarlas vía MCPs puede multiplicar la calidad de los resultados. Conectar Jira o Linear para traer las historias de usuario tal cual están escritas. Conectar Context7 para que el LLM tenga la documentación actualizada de tus frameworks y no dependa de su entrenamiento. Conectar Figma para que pueda leer los diseños directamente (no como imagen, sino entendiendo capas, colores, tipografía). Conectar Playwright para testing automático de UI. Conectar Sentry para errores y Snyk para vulnerabilidades.
Todo esto no es SDD per se, pero es el entorno que hace que el SDD funcione de verdad.
Paso 3: Escribe specs ligeras y orientadas a la ejecución
Para cualquier funcionalidad no trivial, escribo una spec. Pero una spec ligera: una página, no diez. Que contenga:
- El por qué y el qué (2-3 frases)
- Restricciones claras (librerías a usar, patrones a seguir, lo que está fuera de alcance)
- Tareas numeradas con criterios de verificación
Cada tarea debería ser lo suficientemente pequeña como para ejecutarse en una sesión de coding, revisarse fácilmente, y hacer commit de forma independiente.
La clave es que la spec es un documento vivo. Si al implementar la tarea 1 descubres que algo necesita cambiar, vuelves a la spec, la actualizas, y sigues. No es waterfall. Es iteración guiada.
Paso 4: Ejecuta tarea por tarea, no todo de golpe
Este es probablemente el consejo más importante. No le des toda la spec al agente y le digas «implementa esto». Dale una tarea a la vez:
«Lee la spec y ejecuta la tarea 1»
Revisa el resultado. Haz commit. Abre una nueva sesión si es necesario. Ejecuta la tarea 2. Este enfoque incremental es exactamente como funcionan los buenos equipos de ingeniería: un tech lead descompone el trabajo, cada desarrollador recibe una tarea acotada, la implementa, se revisa, y se avanza.
La ventaja adicional es que si algo sale mal, el impacto es pequeño. Es mucho más fácil corregir el rumbo en la tarea 3 que descubrir al final que las 10.000 líneas que generó el agente tienen problemas fundamentales de arquitectura.
Paso 5: Empieza por la UI, no por la infraestructura
Un consejo práctico que he validado repetidamente: cuando trabajes con IA en un proyecto nuevo, empieza por el frontend con datos dummy (JSON estático). Esto te permite:
- Visualizar cómo va a funcionar la app antes de invertir en backend
- Iterar rápidamente en el diseño y la experiencia de usuario
- Descubrir requisitos que no habías considerado al ver la interfaz funcionando
- Informar mejor las decisiones de modelo de datos y API
Una vez que tengas claro cómo se ve y se siente la aplicación, conectar el backend es mucho más predecible.
Cuándo usar SDD y cuándo no
No todo necesita una spec. Esta es mi guía práctica:
Solo vibe coding (sin spec):
- Prototipos rápidos y pruebas de concepto
- Scripts de una sola sesión
- Correcciones de bugs simples y conocidos
- Exploración de ideas
Spec ligera (1 página con tareas):
- Funcionalidades nuevas de tamaño medio
- Integraciones con servicios externos
- Cambios que afectan a múltiples archivos
- Cualquier cosa que vayas a desarrollar en más de una sesión
Spec completa (con fase de planificación e investigación previa):
- Funcionalidades grandes y complejas
- Cambios arquitectónicos significativos
- Features que involucran modelado de datos nuevo
- Trabajo en equipo donde otros necesitan entender las decisiones
Nunca (el SDD no sustituye esto):
- Investigación de usuarios y validación de producto
- Decisiones de negocio sobre qué construir
- Diseño de UX y pruebas de usabilidad
El futuro del SDD: entre la promesa y la realidad
El SDD está en un momento interesante. GitHub lo ha adoptado con Spec-Kit. Amazon lo ha integrado en Kiro. Cursor ha añadido funcionalidades de planificación. Claude Code tiene su planning mode. La industria está convergiendo en la idea de que «prompt and pray» no es sostenible.
Pero el tooling todavía no está maduro. Las herramientas son demasiado rígidas, los workflows no se adaptan al tamaño del problema, y hay una tendencia preocupante a sobreingenierizar el proceso de especificación. Ironía pura: creamos frameworks pesados para evitar la complejidad del código generado por IA, y acabamos con otro tipo de complejidad.
Lo que necesitamos son herramientas que:
- Se adapten al tamaño del problema en lugar de aplicar el mismo proceso a todo
- Faciliten la iteración rápida, no la planificación exhaustiva up-front
- Integren la especificación en el flujo de trabajo de forma natural, sin crear una capa extra de burocracia
- Aprendan de las preferencias del equipo y del proyecto con el tiempo
Mientras tanto, mi recomendación es pragmática: toma los principios del SDD (pensar antes de codificar, definir restricciones claras, descomponer el trabajo, verificar paso a paso) y aplícalos con la ligereza que cada situación requiera. No necesitas un framework para escribir un buen briefing antes de pedirle algo a un agente de IA.
La especificación no es el producto. El producto es el producto. Y el mejor proceso es el que te ayuda a llegar ahí más rápido y con más calidad, no el que genera más documentos intermedios.
Todavía no tengo claro si el nivel spec-as-source terminará encontrando su sitio o será otra moda que recordaremos dentro de 5 años con cierta ironía.
Si trabajas con agentes de IA para desarrollo de software y quieres compartir tu experiencia con SDD (o con cualquier otro enfoque), me encantaría leerlo en los comentarios. Esto evoluciona tan rápido que lo que escribo hoy puede quedar obsoleto en semanas, y la experiencia colectiva vale más que cualquier tutorial.



Me gusta mucho como has traído el conocimiento de forma clara y pragmática. Hay mucha basura de IA siendo compartida todos los días y es dificil encontrar joyas como estas.
Me he recordado a una vez, una única vez, que tuve un proyecto que las especificaciones estaban bien documentadas antes de empezar a implementarlas. Ese proyecto fue perfecto, entregado a tiempo y sin complicaciones.
La opción de tener SDD como herramienta disponible es algo que puede dar buena estructura para usar la IA en el desarrollo de productos. Quien sabe los Project Manager puedan reciclarse y volver a ser relevantes en el ciclo de desarrollo.
Gracias! La verdad es que tener unas buenas especificaciones como comentas, para mí es la clave. El problema viene cuando muchas veces, estas especificaciones están también escritas por IA, entonces, el bucle se realimenta…