 por
por En el mundo del desarrollo de software aparecen conceptos que se vuelven rápidamente populares. De repente, todos queremos aplicarlos, pero muchas veces lo hacemos sin comprender del todo por qué ni cómo. CQRS (Command Query Responsibility Segregation) es uno de esos conceptos.
Si alguna vez has escuchado decir: «Hacemos CQRS porque tenemos separadas las carpetas /commands y /queries«, este artículo es precisamente para ti.
Un breve repaso: ¿De dónde viene CQRS?
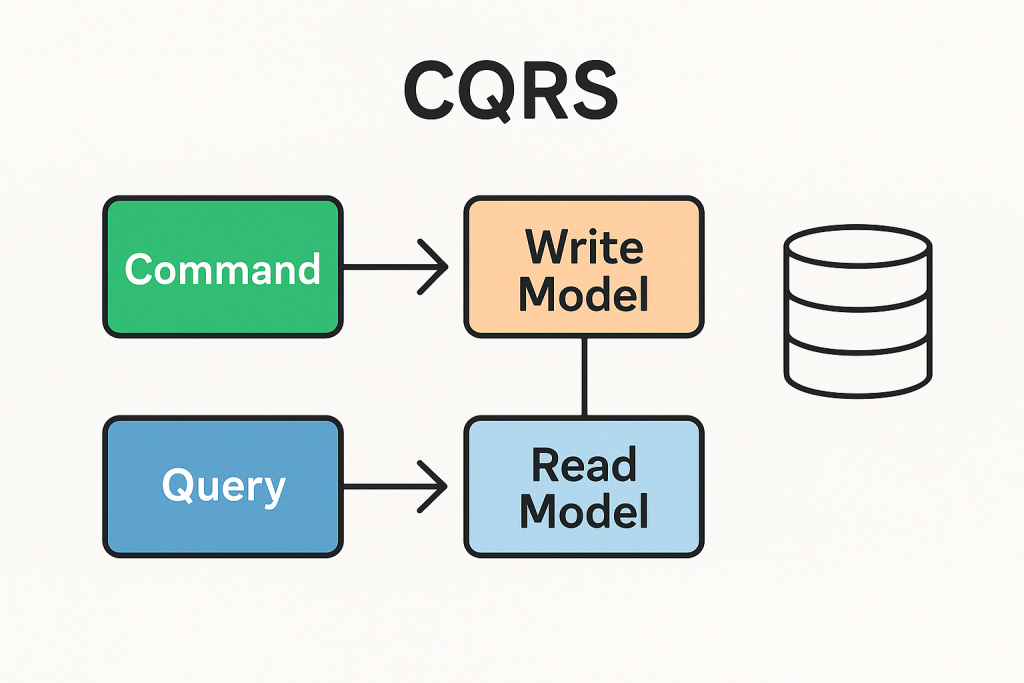
CQRS se basa en una idea sencilla, pero muy poderosa: separar claramente las operaciones que modifican el estado del sistema (commands) de aquellas que únicamente consultan información (queries).
Esto no es nuevo. De hecho, proviene del principio CQS (Command Query Separation) introducido hace décadas por Bertrand Meyer, quien afirmó que un método debería hacer una sola cosa: modificar estado o devolver datos, pero no ambas.
¿Cuál es la diferencia entre CQS y CQRS?
Mientras CQS es un principio que se aplica a nivel de métodos individuales (no mezclar operaciones que cambian estado con aquellas que sólo consultan información), CQRS lleva esta idea más allá, aplicándola a la estructura completa del sistema, incluyendo modelos de dominio, infraestructuras y bases de datos.
La confusión más habitual
Muchas aplicaciones organizan su código en dos carpetas: /commands y /queries. Esto es útil desde un punto de vista organizativo y promueve claridad en el código. Pero tener esta separación visual no significa necesariamente que estés aplicando CQRS de verdad.
CQRS implica una separación más profunda: no solo en el código, sino también en la infraestructura, el diseño, la semántica y el rendimiento del sistema.
En el libro «CQRS by Example«, Carlos Buenosvinos y Christian Soronellas explican que CQRS separa el modelo del dominio en operaciones de lectura y operaciones de escritura para maximizar tres aspectos clave: semántica, rendimiento y escalabilidad.
¿Qué implica realmente aplicar CQRS?
¿Cómo complementa CQRS a DDD?
Domain-Driven Design (DDD) busca representar de forma fiel el conocimiento del dominio dentro del código, encapsulando reglas e invariantes de negocio en agregados coherentes. Sin embargo, cuando intentamos usar ese mismo modelo de dominio tanto para modificar como para consultar datos, el modelo acaba distorsionado: lleno de getters, joins y lógica de presentación que no le corresponden. Aquí es donde CQRS marca una diferencia. Al separar claramente los modelos de lectura y escritura, CQRS libera al modelo de dominio de responsabilidades ajenas, permitiéndole centrarse únicamente en las reglas del negocio. Esto refuerza la pureza de los agregados, promueve una verdadera separación de responsabilidades y evita el acoplamiento con necesidades técnicas de las vistas. En conjunto, CQRS y DDD forman una combinación poderosa: uno estructura la arquitectura en torno al comportamiento del dominio, y el otro protege esa estructura facilitando la evolución independiente de la lectura.
Cuando decides aplicar CQRS, tu sistema queda dividido en dos partes especializadas:
El modelo de escritura (Write Model)
Aquí se ubican todas las operaciones que cambian el estado del sistema. Este modelo es habitualmente rico en reglas de negocio, invariantes, y lógicas complejas para asegurar la integridad y la consistencia de los datos.
El modelo de lectura (Read Model)
Esta parte se encarga exclusivamente de consultas rápidas. Generalmente, es un modelo más simple, desnormalizado, y optimizado para facilitar consultas rápidas y eficientes. Algo interesante es que puedes implementar estos modelos de lectura sin necesidad de usar repositorios tradicionales, utilizando directamente consultas optimizadas o «read layers» especializadas para mejorar el rendimiento.
Un ejemplo real: pedidos en un eCommerce
Imagina que estás desarrollando un sistema de pedidos. Tienes un agregado Order que cumple con todas las reglas de negocio:
- No se puede pagar un pedido vacío.
- No puedes modificarlo si ya ha sido enviado.
- Cada producto solo puede añadirse una vez, etc.
Todo limpio y coherente.
Ahora llega la parte de negocio y te pide una tabla para la interfaz de usuario: mostrar todos los pedidos con su número, cliente, estado, total y el último producto añadido. Además, con filtros por fecha y por importe.
Si intentas satisfacer esto desde el propio modelo Order, acabarás con métodos tipo getLastProduct(), getTotalAmount(), getCustomerName()… navegando por relaciones que no deberían estar ahí, cargando datos que no hacen falta, y acoplando el dominio a cómo se pinta una tabla.
Si aplicas CQRS, lo resuelves de forma mucho más limpia:
- El agregado
Ordersigue enfocado en su lógica: no se ve afectado. - Las queries se hacen contra una proyección de lectura optimizada, que puede incluso venir de una vista materializada o una tabla específica para el dashboard.
Así mantienes la lógica del negocio protegida, y la interfaz de usuario rápida y flexible.
DDD te da la estructura y el lenguaje para modelar el comportamiento del dominio, mientras que CQRS te permite mantener ese modelo limpio, evitando que se ensucie con detalles técnicos o necesidades de presentación.
Separar lectura y escritura no solo es una cuestión técnica. Es una decisión de diseño que protege el corazón del negocio y te da mayor libertad para evolucionar el sistema sin miedo a romperlo todo.
¿Es obligatorio tener proyecciones o bases de datos separadas?
No. Aunque CQRS suele asociarse a modelos de lectura optimizados o incluso bases de datos distintas, no es un requisito obligatorio. Puedes aplicar CQRS dentro de una misma base de datos y sin vistas materializadas, simplemente separando las operaciones de lectura y escritura en tu diseño y tu código.
Lo importante no es la infraestructura, sino la separación clara de responsabilidades. La sofisticación técnica vendrá si realmente lo necesitas por rendimiento o escalabilidad.
Un ejemplo práctico: «Cheeper» (inspirado en Twitter)
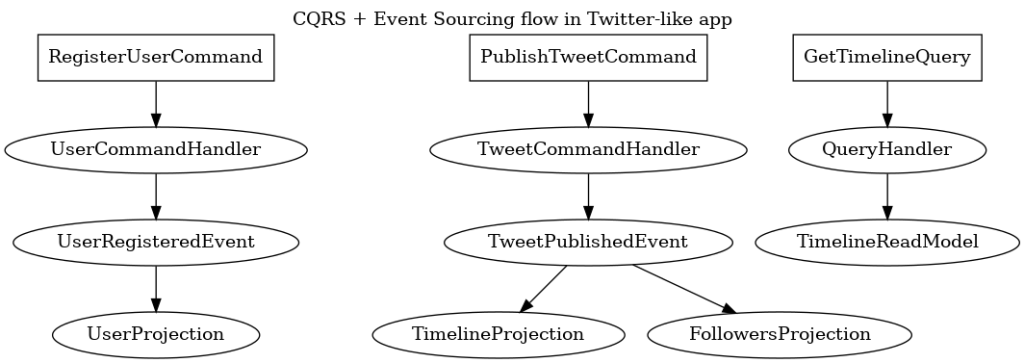
En «CQRS by Example» encontramos un ejemplo de aplicación llamada Cheeper (una especie de clon simplificado de Twitter):
- Cuando un usuario publica un «cheep» (un mensaje), la operación es compleja (valida y ejecuta una serie de acciones). Esta es la parte de escritura.
- Cuando miles de usuarios consultan su timeline, lo que importa es mostrar datos rápidamente sin aplicar todas esas reglas cada vez. Esta es la parte de lectura.
Al utilizar CQRS, el modelo de escritura guarda el cheep y genera un evento (CheepPublicado). El modelo de lectura escucha estos eventos y actualiza una vista optimizada para consultas rápidas.
¿Y qué pasa si tu aplicación es sencilla?
CQRS no es obligatorio ni siempre recomendable, al igual que DDD. Para aplicaciones CRUD simples, el coste de implementarlo supera sus beneficios. Basta con respetar el principio CQS a nivel de métodos para mantener una buena calidad del código.
¿Y si no sincronizo bien los modelos?
Uno de los retos clave de CQRS es mantener los modelos de lectura sincronizados con los eventos de escritura. Esto implica estrategias de resiliencia como colas idempotentes, reintentos automáticos y monitoreo constante.
Consejos finales para decidir bien
- CQRS es una decisión arquitectónica consciente y estratégica, no una moda.
- Antes de aplicarlo, evalúa si tienes necesidades reales que lo justifiquen (alta demanda de lectura, modelos de negocio complejos).
- No lo implementes solo porque «queda bien» o porque es popular.
Conclusión
Separar commands y queries en carpetas es útil, pero no garantiza que estés aplicando CQRS. CQRS es más profundo: afecta cómo diseñas y gestionas tus modelos, tu infraestructura y cómo evolucionas tu aplicación.
Antes de lanzarte, pregúntate: ¿Mi sistema realmente lo necesita? La respuesta a esta pregunta marcará la diferencia entre añadir valor o añadir complejidad innecesaria.
¿Tienes experiencias positivas o negativas con CQRS? ¡Comparte tu opinión y hablemos más en los comentarios!

esto de sincronizar bien los modelos de lectura con los eventos es lo que mas me cuesta, a ver si algun dia haces un post sobre eso
muy interesante como se complementa con ddd, nunca lo habia visto tan claro